

If you’ve ever wondered how AI understands and generates human language, you are not alone. Since ChatGPT exploded on the scene in Nov 2022, large language models have caught the imagination of people at large. In 2024, they are being touted as game-changers, transforming everything language, from chatbots to content creation.
Imagine this: You have an AI assistant that sets up meetings, writes social media posts, translates between languages like a pro, transcribes hour long videos in minutes, analyzes complex documents quickly to advise you on next steps or answers questions on mind-boggling topics in seconds.
Doesn’t success and balanced life feel so much within reach?
AI assistant can be your many-in-one employee that takes so much off your plate on any given day. Personally as well as professionally. But to get real work done, you need to know what makes these assistants (aka your employees) tick.
In one word or three, the straightforward answer is large language models or LLMs.
To help you understand how your AI assistant works, I wrote this guide on what are large language models, which breaks down the (perceived) magic behind LLMs, explores their benefits and offers actionable tips to harness their power.
Ready to dive into the world of large language models? Let’s get started!
Understanding Large Language Models
Large language models are artificial intelligence systems that can understand, analyze and manipulate human language to generate natural language in the form of text, image, audio or video.
These models are built using machine learning techniques, particularly deep learning, and are trained on vast amounts of data to develop a sophisticated understanding of language patterns, context and nuances. The keyword here is “patterns” and we will keep coming back to it.
But before we proceed, know that the “large” in LLMs does not refer to vast amount of training data. It refers to large number of parameters that the modern LLMs have.
So what are parameters in LLMs?
Parameters are the internal variables (or controls, if you want it to remain strictly non-tech!!) of any model, which it adjusts to get the right output.

Think of parameters like the tens and hundreds or knobs and dials and sliders on a DJ controller setup. A more sophisticated setup has a larger number of these controllers and is more complicated to handle, but in the hands of a pro, gives much better output.
Similarly, an LLM mode with larger number of parameters has better (read more accurate, human-language-like, hallucination-free) output as compared to a model with lower number of parameters. To get a feel of number of parameters in the large language models, know that ChatGPT-3 has 175 billion parameters and ChatGPT-4 has 100 trillion parameters. No wonder these models give outputs that are so human-like.
Where Did LLMs Come From?
The journey of large language models began with the development of early natural language processing (NLP) systems in 1980s. Initially, these systems relied on rule-based approaches and simple statistical methods. They were more like large algorithms with complex if-then-else loops.
The real breakthrough came with the advent of deep learning and neural networks.
And the transformer architecture introduced by Google in 2017, via its paper Attention is All You Need proved to be the real gamechanger.
In 2018, OpenAI introduced GPT (Generative Pre-trained Transformer) model, which proved to be a significant development. GPT-3, released in 2020, showcased the immense potential of LLMs by generating human-like text, sparking widespread interest and further research. Subsequent advancements have focused on increasing the size and complexity of these models, improving their accuracy and capabilities.
Key Characteristics of LLMs
Here are the four most important characteristics of large language models:
- Large-scale Training: LLMs are trained on massive datasets that include diverse sources such as books, articles, audio, videos, whitepapers, reports and complete websites. This extensive training enables them to understand a wide range of topics and contexts. What we actually mean by “understand,” we will discuss in a bit.
- Transformer Architecture: Most LLMs utilize the transformer architecture, which is a neural network that learns the relationships in a sequential set of data. Any of the sentences in this article is a sequential set of data. Based on their understanding of this relationship, they can predict or generate text. Basically, they are trained on trillions of sentences so that they can predict the next set of words like in Gmail or Google search autocomplete.
- Contextual Understanding: LLMs are capable of grasping context too, which allows them to generate coherent and contextually relevant text. For instance, if you say “I want to buy a bat” it will understand you are talking about the sports thing, as opposed to the animal. That’s why they can maintain the flow of conversation and provide meaningful responses.
- Versatility: These models can perform a variety of tasks, including text completion, translation, summarization, sentiment analysis and more. Their versatility makes them valuable in numerous applications.
How Large Language Models Work
Large language models (LLMs) rely on the principles of machine learning and neural networks to process and generate human language. Using mathematical functions they learn to identify patterns (of text, audio, pixels, or whatever we are trying to train them on), context and relationships within vast datasets. This process of learning or understanding involves multiple layers of neurons that mimic the human brain’s structure, allowing the model to recognize complex patterns in text data.
If you want to know more about how these models mimic the neurons in our brain, read this blog post on Artificial Neural Networks.
Typical Training Process of LLMs
LLMs undergo a two-step training process: pre-training and fine-tuning.
Step 1: Pre-training
During this stage, the model is exposed to a massive corpus of text data from various sources, such as books, articles and websites. The model learns to predict the next word in a sentence, which helps it understand language structure, grammar and context.
See the suggestions when I type “content” in Google search.
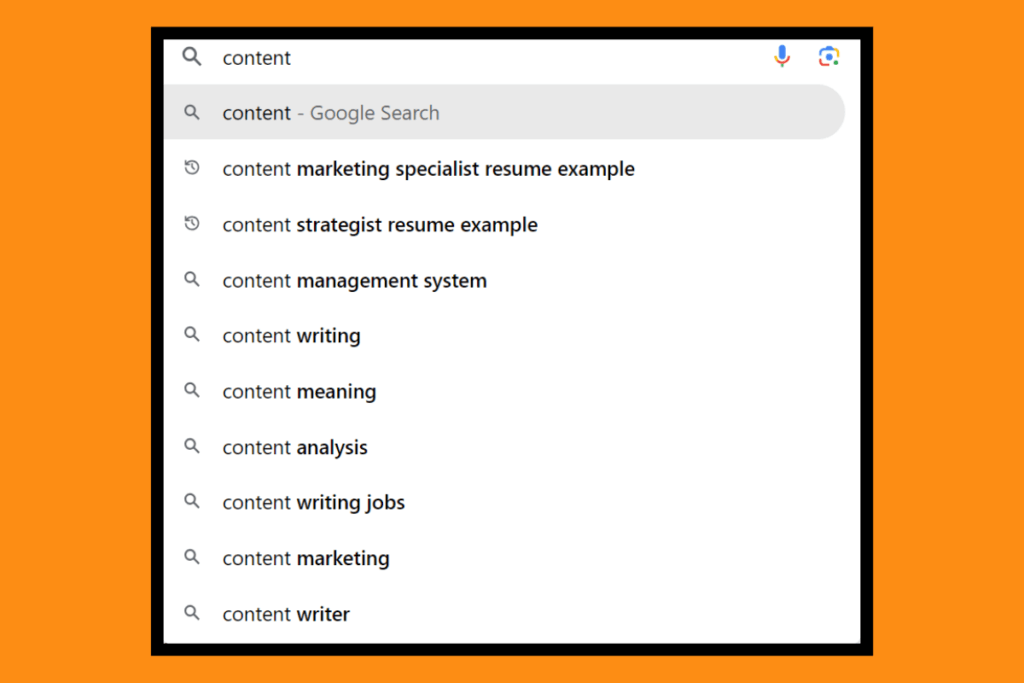
The moment I type the next word, the suggestions for autocomplete change.
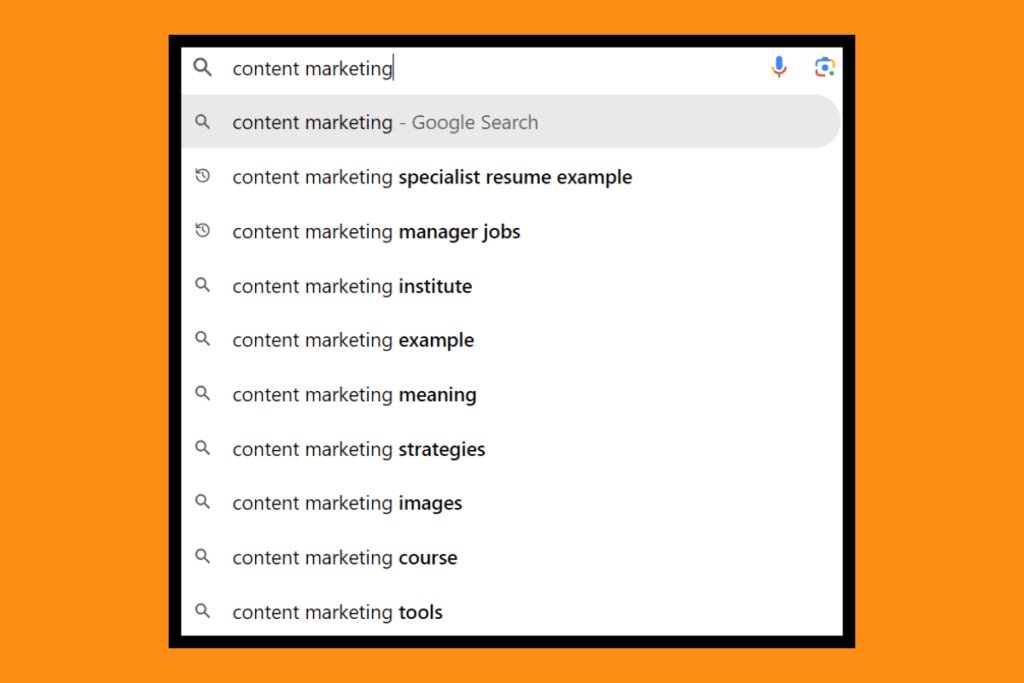
With three words, I have even more refined suggestions:
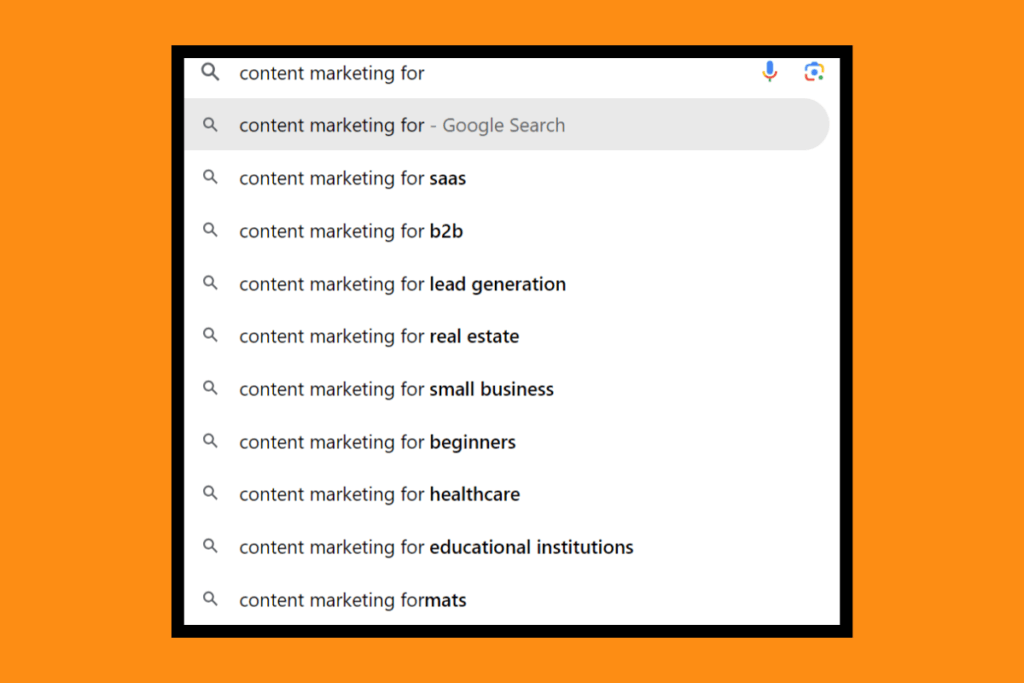
But when I add one more word, the model starts looking for long range dependencies:
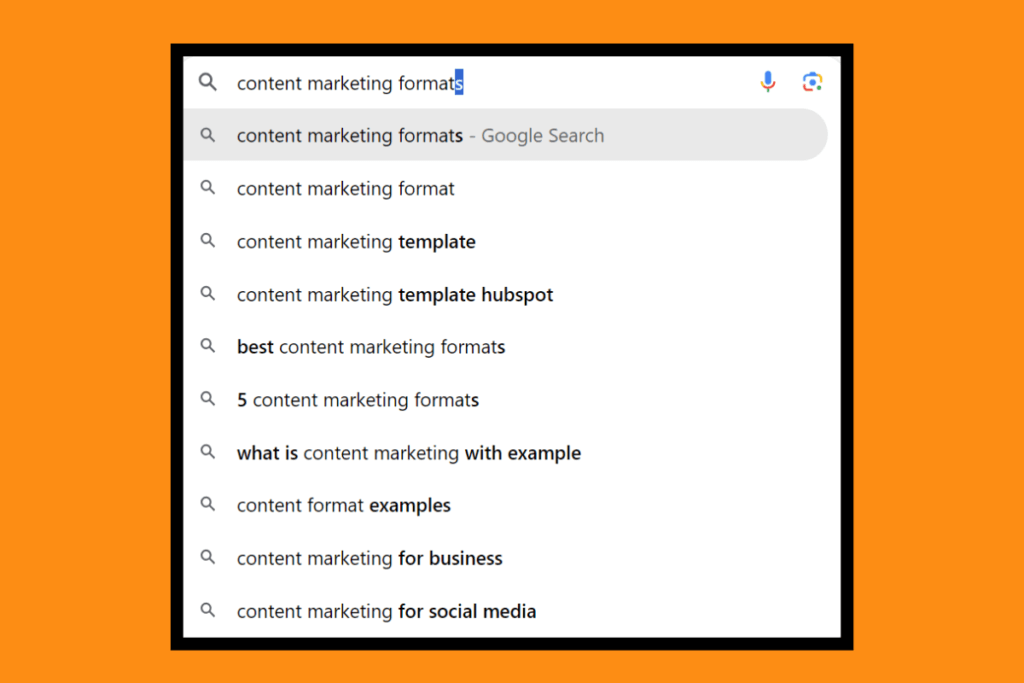
This stage requires significant computational power and time, often taking weeks or months to complete. What we get after pre-training are the foundational models, which can then be used to develop more expert or focused models. Focused on doing a singular or just a couple of things.
Step 2: Fine-tuning
After pre-training, the model undergoes fine-tuning on a smaller, task-specific dataset. This process helps the model adapt to particular applications, such as sentiment analysis, text summarization, language translation, chatbot development, etc. Fine-tuning enhances the model’s performance and ensures it is well-suited to specific tasks.
Key Techniques Used in Training Algorithms
You have understood by now that LLMs are just about algorithms and models; any model typically uses multiple algorithms. There are many techniques used to optimize model performance, improve generalization, prevent overfitting (learning the training data so well that providing output on new data gives poor results), enhance contextual understanding, so that the LLMs can effectively learn from data and perform well on various tasks.
Contextual understanding is very critical to generating human language as we all know. So many words in English mean different things in different context. Look at how ChatGPT understands this beautifully.

Here I am listing a few techniques used by training algorithms so that you start appreciating the amount of effort that must go into making a machine “intelligent.” Know that what I list here is but a miniscule fraction of the number of techniques used to train LLMs.
- Transformer Model: The transformer model is the backbone of most LLMs. Introduced in the paper “Attention Is All You Need,” transformers excel at handling sequential data and capturing long-range dependencies in text. They use self-attention mechanisms to weigh the importance of different words in a sentence, allowing the model to generate coherent and contextually relevant text.
- Self-Attention Mechanism: Self-attention allows the model to focus on different parts of a sentence when processing each word. This mechanism helps the model understand context and relationships between words, improving its ability to generate meaningful and accurate text.
- Layer Normalization and Dropout: These techniques are used to stabilize and regularize the training process. Layer normalization helps the model converge faster by normalizing the input to each layer, while dropout prevents overfitting by randomly dropping units during training.
- Positional Encoding: Since transformers do not have a built-in understanding of word order, positional encoding is used to provide information about the position of words in a sentence. This helps the model understand the correct sequence of words for the language, which is crucial for maintaining the coherence of generated text. Otherwise, you will have a jumbled set of words as output!!
- Sequence-to-Sequence (Seq2Seq) Learning: This involves training the model to convert input sequences (e.g., a question) into output sequences (e.g., an answer), which is useful for tasks like translation and summarization.
- Next Sentence Prediction (NSP): It trains the model to predict whether a given sentence logically follows from a preceding sentence, enhancing its understanding of sentence-to-sentence relationships.
- Reinforcement Learning from Human Feedback (RLHF): Human feedback is used to fine-tune the model’s responses, optimizing for desired behavior through reinforcement learning techniques. Reinforcement learning in machine learning is similar to what we do for humans. The model learns to make decisions by receiving rewards or penalties based on its actions or outputs.
Examples of Popular Large Language Models
These are a few popular LLMs:
- GPT-3 (Generative Pre-trained Transformer 3): Developed by OpenAI, GPT-3 is one of the most well-known LLMs. It has 175 billion parameters and can generate highly coherent and contextually relevant text, making it suitable for a wide range of applications.
- BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT is designed to understand the context of a word based on its surrounding words. This bidirectional approach enhances its ability to understand and generate human language, particularly for tasks like question answering and sentiment analysis.
- T5 (Text-to-Text Transfer Transformer): Developed by Google, T5 treats all NLP tasks as a text-to-text problem. This unified approach allows it to perform a variety of tasks, from translation to summarization, using a single model.
- RoBERTa (Robustly Optimized BERT Approach): An optimized version of BERT, RoBERTa improves on BERT’s performance by training on more data and using a different training strategy. It achieves state-of-the-art results on many NLP benchmarks.
Benefits of Large Language Models
Large language models offer numerous advantages that can significantly enhance various applications and industries. Here are some of the key benefits of using LLMs:
Improved Efficiency in Natural Language Processing Tasks
LLMs streamline and automate a wide range of natural language processing (NLP) tasks, reducing the need for manual intervention. This includes tasks such as text classification, sentiment analysis and entity recognition. By leveraging LLMs, businesses can process large volumes of text data quickly and accurately, saving time and resources.
Enhanced Accuracy in Understanding and Generating Human Language
One of the standout features of LLMs is their ability to understand and generate human language with high accuracy. This is achieved through advanced training techniques and large-scale datasets. As a result, LLMs can produce coherent and contextually relevant text, making them ideal for applications like chatbots, virtual assistants, and content generation.
Streamlined Customer Service Operations through Automation
LLMs can significantly improve customer service operations by automating responses to common queries and providing instant support. Chatbots powered by LLMs can handle customer inquiries, offer personalized recommendations and escalate complex issues to human agents when necessary. This can lead to faster response times, improved customer satisfaction and reduced operational costs.
Increased Efficiency in Content Creation
Content creation is a time consuming process that can be greatly enhanced by LLMs. These models can assist in generating ideas, analyzing top-ranking posts, generating outlines that incorporate keywords naturally, editing, proofreading, re-purposing existing content, identifying value-adds and more. I can vouch for these because I have used AI agents for all of these.
Advanced Capabilities in AI-Driven Applications

LLMs are integral to the development of sophisticated AI-driven applications. Their ability to process and understand natural language enables the creation of advanced tools and platforms across various domains. For example:
- Healthcare: LLMs can assist in analyzing medical records, extracting relevant information and providing diagnostic suggestions.
- Research: LLMs can assist in scientific research by analyzing vast amounts of literature to identify trends, generate hypotheses, and provide insights. For example, they can help in drug discovery by predicting molecular interactions and in climate science by modeling complex environmental data.
- Legal: They can help in reviewing legal documents, identifying key clauses and summarizing lengthy texts.
- Finance: LLMs can analyze financial reports, extract insights and generate detailed summaries for decision making.
By leveraging the advanced capabilities of LLMs, organizations can develop innovative solutions that drive efficiency, accuracy and productivity.
Applications of Large Language Models
Large language models (LLMs) have a wide range of applications across various industries due to their advanced natural language processing capabilities. Here are some practical uses of LLMs:
- Chatbots and Virtual Assistants: Provide automated, human-like customer service and support.
- Content Creation: Generate articles, video scripts and social media content based on given prompts.
- Translation Services: Translate text between multiple languages with high accuracy.
- Sentiment Analysis: Analyze customer reviews and social media posts to determine public sentiment.
- Summarization: Condense long documents or articles into shorter, concise summaries.
- Code Generation: Assist in writing and debugging code by generating code snippets and providing programming suggestions.
- Personalized Recommendations: Offer tailored product or content suggestions based on user preferences and behavior.
- Educational Tools: Create interactive learning experiences and personalized tutoring for students.
- Medical Diagnosis Support: Analyze medical records and literature to aid in diagnosing and suggesting treatments.
- Legal Document Analysis: Review and summarize legal documents, contracts, and case law to assist legal professionals.
Challenges and Limitations
While large language models (LLMs) offer significant advantages, they also come with their own set of challenges and limitations. Understanding these issues is crucial for effectively leveraging LLMs and addressing potential drawbacks.
Complexity in Understanding and Implementing LLMs
One of the primary challenges with LLMs is their complexity. The underlying technology involves advanced concepts in machine learning and neural networks, which can be difficult for non-experts to grasp. Implementing LLMs effectively requires specialized knowledge and expertise in data science, making it a barrier for many organizations.
High Computational Costs and Resource Requirements
Training and deploying large language models demand substantial computational power and resources. The pre-training phase, in particular, can be extremely resource-intensive, often requiring specialized hardware like GPUs or TPUs. This high cost can be prohibitive for small and medium-sized businesses, limiting their ability to utilize LLMs effectively.
Ethical Concerns and Biases in LLMs
LLMs can inadvertently perpetuate biases present in their training data. If the data includes biased or unrepresentative information, the model can produce biased outputs, which can be problematic in sensitive applications such as hiring, lending, or law enforcement. Addressing these ethical concerns requires ongoing monitoring and the development of techniques to mitigate bias.
Like an intelligent kid is faster to pick up cuss words and slangs, even when you uttered them just once or twice, the LLMs, precisely due to their capabilities like long range dependencies can pick up on human biases real quick if they are trained on real world data. Which ALL foundational models are!!
Accessibility Issues for Small Businesses and Startups
The cost and complexity of LLMs create accessibility issues, particularly for small businesses and startups. These organizations may lack the financial resources or technical expertise needed to implement LLMs effectively. This disparity can widen the gap between large enterprises and smaller entities, making it challenging for the latter to compete.
Potential Misuse and Security Risks
The advanced capabilities of LLMs also present risks of misuse. For example, LLMs can be used to generate misleading or harmful content, including fake news, deepfakes or phishing attacks. Additionally, the large amounts of data processed by LLMs can pose security risks if not managed properly. Ensuring the ethical use of LLMs and implementing robust security measures are essential to mitigating these risks.
Future Trends and Developments
Large language models are continuously evolving, with ongoing research and development driving new advancements. Here are some key trends and developments to watch for in the future of LLMs:
Advances in LLM Technology and Capabilities
Researchers are working on improving the architecture of these models to enhance their performance while reducing computational costs. Game changing innovations and more efficient training algorithms are expected to play a significant role in the next generation of LLMs.
Integration with Other AI Technologies
Future developments will likely see LLMs integrated with other AI technologies, such as computer vision, robotics, and reinforcement learning. This integration will enable more sophisticated AI systems capable of performing a wider range of tasks. For example, combining LLMs with computer vision can enhance image captioning and understanding, while integration with robotics can lead to more advanced human-robot interactions.
Emerging Applications and Use Cases
As LLMs become more powerful and accessible, new applications and use cases will emerge. Potential areas of growth include:
- Healthcare: Advanced diagnostic tools, personalized treatment plans, and improved patient care through better understanding of medical records and research.
- Legal: More efficient legal research, contract analysis, and case law summarization.
- Education: Personalized learning experiences, intelligent tutoring systems, and automated grading and feedback.
Predictions for the Future of LLMs
The future of large language models is full of exciting possibilities, driven by continuous advancements in technology and growing awareness of ethical considerations. With passage of time LLMs are expected to become more ubiquitous and integrated into everyday applications:
- Wider Adoption: As LLMs become more accessible and affordable, a broader range of industries and organizations will adopt them.
- Improved Human-AI Collaboration: Enhanced LLMs will facilitate more seamless collaboration between humans and AI, improving productivity and creativity.
- Regulation and Standards: There will be a growing need for regulations and standards to ensure the ethical use of LLMs and to address privacy and security concerns.
A Quick Summary (so far…)
Large language models have revolutionized natural language processing, offering powerful tools for understanding and generating human language. These models, such as GPT-3 and BERT, leverage advanced deep learning techniques to achieve high accuracy and contextual understanding. LLMs improve efficiency in NLP tasks, enhance language comprehension, streamline customer service, and boost content creation productivity.
Despite their benefits, challenges like complexity, high computational costs, and ethical concerns remain. The future of LLMs promises technological advancements, integration with other AI technologies, and wider adoption across various industries. By staying informed and following best practices, you can unlock the full potential of LLMs and transform your approach to language processing tasks.
Final Thoughts
The potential of large language models is immense, and their impact is already being felt across different sectors. By understanding how to effectively implement and leverage these models, businesses and individuals can unlock new levels of productivity, innovation, and efficiency.
As you embark on your journey of LLMs, remember to stay informed about the latest developments as well as best practices. Continuous learning and adaptation will help maximize the benefits you are aiming for.
Time for Action
Do you now feel confident enough to explore the world of large language models? Whether you’re looking to enhance your customer service, streamline content creation or developing SaaS tools using AI, LLMs offer a powerful solution. Start by diving deep into what the available tools are capable of and making a shortlist of what can work for you.

Trackbacks/Pingbacks